Jon Udell wrote a post yesterday “Where’s the IFTTT for repetitive manual text transformation?“. In the post Jon describes how he wanted to update some links on one of his web pages and documents the steps needed to do the update to all links in a systematic way. Jon notes:
Now that I’ve written all this down, I’ll admit it looks daunting, and doesn’t really qualify as a “no coding required” solution. It is a kind of coding, to be sure. But this kind of coding doesn’t involve a programming language. Instead you work out how to do things interactively, and then capture and replay those interactions.
and then asks
Are there tools – preferably online tools – that make this kind of text transformation widely available? If not, there’s an opportunity to create one. What IFTTT is doing for manual integration of web services is something that could also be done for manual transformation of text.
While I don’t think it is completely the solution (and agree with Jon there is a gap in the market here) I think OpenRefine (http://openrefine.org) offers some of what Jon is looking for. Generally OpenRefine is designed for manipulating tabular data, but in the example Jon gives at least, the data is line based, and sort of tabular if you squint at it hard.
I think OpenRefine hits several of the things Jon is looking for:
- it lets you build up complex transformations through small steps
- it allows you to rewind steps as you want
- it allows you to export a JSON representation of the steps which you can share with others or re-apply to a future project of similarly structured data.
These strengths were behind choosing OpenRefine as part of the data import process in the http://gokb.org project I’m currently working on where data is coming in different formats from a variety of sources, and domain experts, rather than coders, are the people who are trying to get the data in a standard format before adding to the GOKb database.
So having said in a comment on Jon’s blog that I thought OpenRefine might fit the bill in this case, I thought I’d better give it a go – and it makes a nice little tutorial as well I think…
I started by creating a new project via the ‘Clipboard’ method – this allows you to paste data directly into a text box. In this case the only data I wanted to enter was the URL of Jon’s page (http://jonudell.net/iw/iwArchive.html)
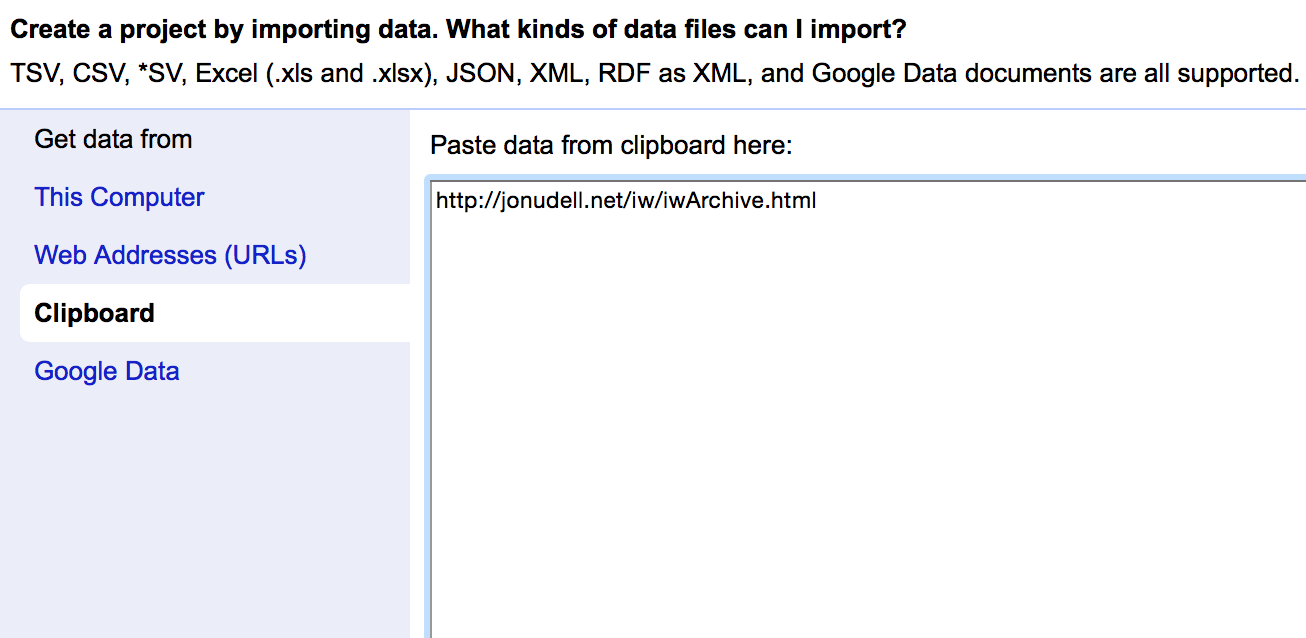
I then used the option to ‘Add column by fetching URLs’ to grab the HTML of the page in question
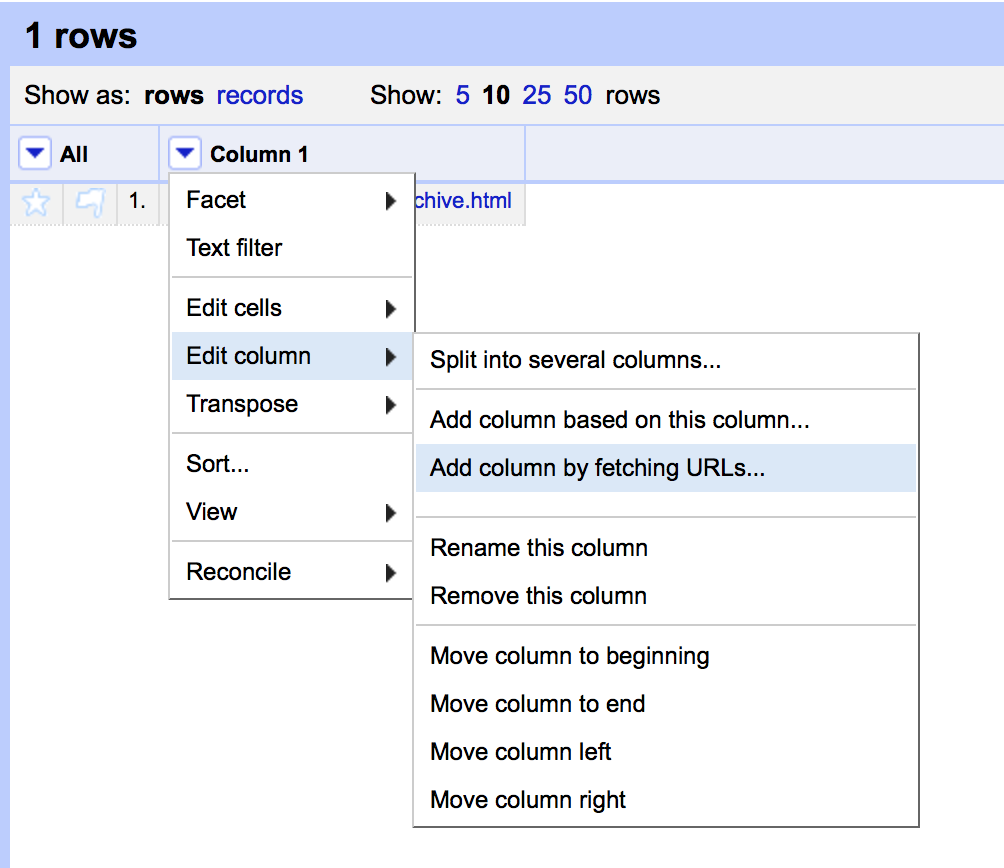
I now had the HTML in a single cell. At this point I suspect there are quite a few different routes to getting the desired result – I’ve gone for something that I think breaks down into sensible steps without any single step getting overly complicated.
Firstly I used the ‘split’ command to break the HTML into sections with one ‘link’ per section:
value.split("<p><a href").join("~<p><a href")
All this does is essentially add in the “~” character between each link.
I then used the ‘Split multi-valued cells’ command to break the HTML down into lines in OpenRefine – one line per link:
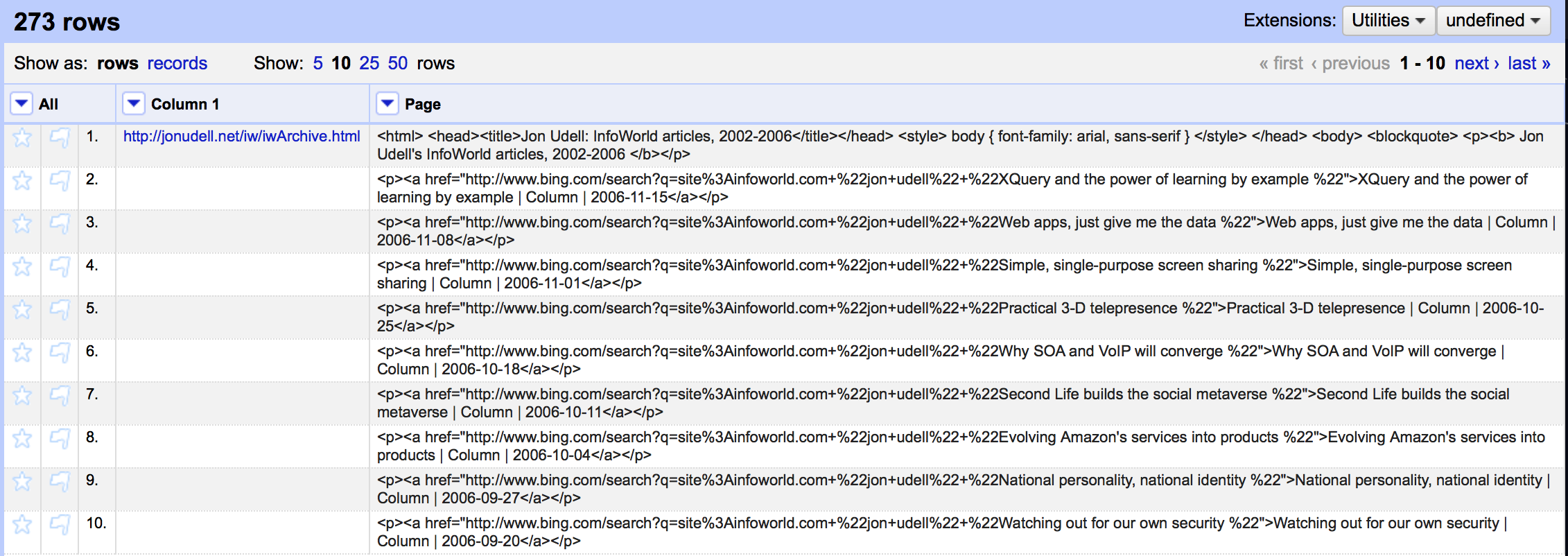
The structure of the links is much easier to see now this is not a single block of HTML. Note that the first cell contains all the HTML >head< and the stuff at the top of the page. If we want to recreate the original page again later we are going to have to join this back up again with the HTML that makes up the links so I’m going to preserve this. Equally at this stage the last cell in the table contains the final link AND the end of the HTML:
<p><a href="http://www.bing.com/search?q=site%3Ainfoworld.com+%22jon+udell%22+%22Web services %22">Web services | Analysis | 2002-01-03</a></p>
</blockquote> </body> </html>
This is a bit of a pain – there are different ways of solving this, but I went for a simple manual edit to add in a ‘~’ character after the final >/p> tag and then using the ‘split multi-valued cells’ again. This manual step feels a bit messy to me – I’d prefer to have done this in a repeatable way – but it was quick and easy.
Now the links are in their own cells, they are easier to manipulate. I do this in three steps:
- First I use a ‘text filter’ on the column looking for cells containing the | character – this avoids applying any transformations to cells that don’t contain the links I need to work with
- Secondly I get rid of the HTML markup and find just the text inside the link using: value.parseHtml().select(“a”)[0].innerHtml()
- Finally I build the link (to Jon’s specification – see his post) with the longest expression used in this process:
"<p><a href=\"http://www.bing.com/search?q=site%3Ainfoworld.com+%22jon+udell%22+%22"+ value.split("|")[0].trim().escape('url')+"%22\">"+ value + "</a></p>"
Most of this is just adding in template HTML as specified by Jon. The only clever bits are the:
value.split(“|”)[0].trim().escape(‘url’)
This takes advantage of the structure in the text – splitting the text where if finds a | character and using the first bit of text found by this method. It then makes sure there are no leading/trailing spaces (with ‘trim’) and finally uses URL encoding to make sure the resulting URL won’t contain any illegal characters.
Once this is done, the last step is to use the ‘join multi-valued cells’ to put the HTML back into a single HTML page. Then I copied/pasted the HTML and saved it as my updated file.
I suspect Jon might say this still isn’t quite slick enough – and I’d probably agree – but there are some nice aspects including the fact that you could expand this to do several pages at the same time (with a list of URLs at the first step instead of just one URL) and that I end up with JSON I can (with one caveat) use again to apply the same transformation in the future. The caveat is that ‘manual’ edit step – which isn’t repeatable. The JSON is:
[
{
"op": "core/column-addition-by-fetching-urls",
"description": "Create column Page at index 1 by fetching URLs based on column Column 1 using expression grel:value",
"engineConfig": {
"facets": [],
"mode": "row-based"
},
"newColumnName": "Page",
"columnInsertIndex": 1,
"baseColumnName": "Column 1",
"urlExpression": "grel:value",
"onError": "set-to-blank",
"delay": 5000
},
{
"op": "core/text-transform",
"description": "Text transform on cells in column Page using expression grel:value.split(\"<p><a href\").join(\"~<p><a href\")",
"engineConfig": {
"facets": [],
"mode": "row-based"
},
"columnName": "Page",
"expression": "grel:value.split(\"<p><a href\").join(\"~<p><a href\")",
"onError": "keep-original",
"repeat": false,
"repeatCount": 10
},
{
"op": "core/multivalued-cell-split",
"description": "Split multi-valued cells in column Page",
"columnName": "Page",
"keyColumnName": "Column 1",
"separator": "~",
"mode": "plain"
},
{
"op": "core/multivalued-cell-split",
"description": "Split multi-valued cells in column Page",
"columnName": "Page",
"keyColumnName": "Column 1",
"separator": "~",
"mode": "plain"
},
{
"op": "core/text-transform",
"description": "Text transform on cells in column Page using expression grel:value.parseHtml().select(\"a\")[0].innerHtml()",
"engineConfig": {
"facets": [],
"mode": "row-based"
},
"columnName": "Page",
"expression": "grel:value.parseHtml().select(\"a\")[0].innerHtml()",
"onError": "keep-original",
"repeat": false,
"repeatCount": 10
},
{
"op": "core/text-transform",
"description": "Text transform on cells in column Page using expression grel:\"<p><a href=\\\"http://www.bing.com/search?q=site%3Ainfoworld.com+%22jon+udell%22+%22\"+ value.split(\"|\")[0].trim().escape('url')+\"%22\\\">\"+ value + \"</a></p>\"",
"engineConfig": {
"facets": [
{
"query": "|",
"name": "Page",
"caseSensitive": false,
"columnName": "Page",
"type": "text",
"mode": "text"
}
],
"mode": "row-based"
},
"columnName": "Page",
"expression": "grel:\"<p><a href=\\\"http://www.bing.com/search?q=site%3Ainfoworld.com+%22jon+udell%22+%22\"+ value.split(\"|\")[0].trim().escape('url')+\"%22\\\">\"+ value + \"</a></p>\"",
"onError": "keep-original",
"repeat": false,
"repeatCount": 10
},
{
"op": "core/multivalued-cell-join",
"description": "Join multi-valued cells in column Page",
"columnName": "Page",
"keyColumnName": "Column 1",
"separator": ""
}
]
One thought on “Using OpenRefine to manipulate HTML”