This is the fourth post in a series of 5.
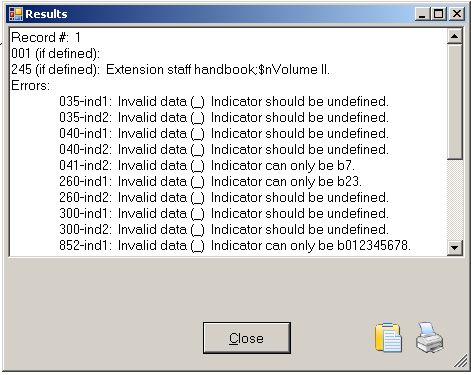
In Part 3 I describe how converted the MARC records into the ‘mnemonic’ format using MarcEdit, and also created a list of issues with the file using the MarcEdit Marc Validator. In this post I’m going to describe how I used OpenRefine to investigate and fix the issues in the file. (n.b. this post dives straight into OpenRefine functionality – I’ve written an introduction to OpenRefine which includes a full tutorial which covers much of the basic functionality)
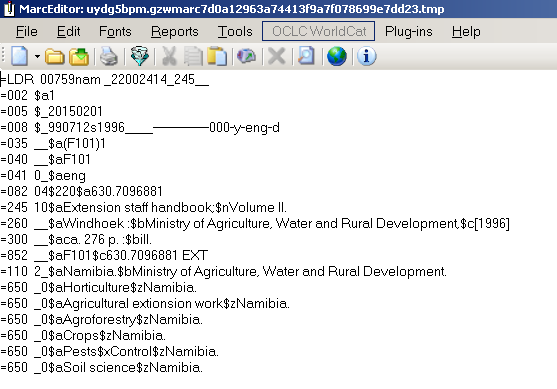
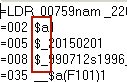
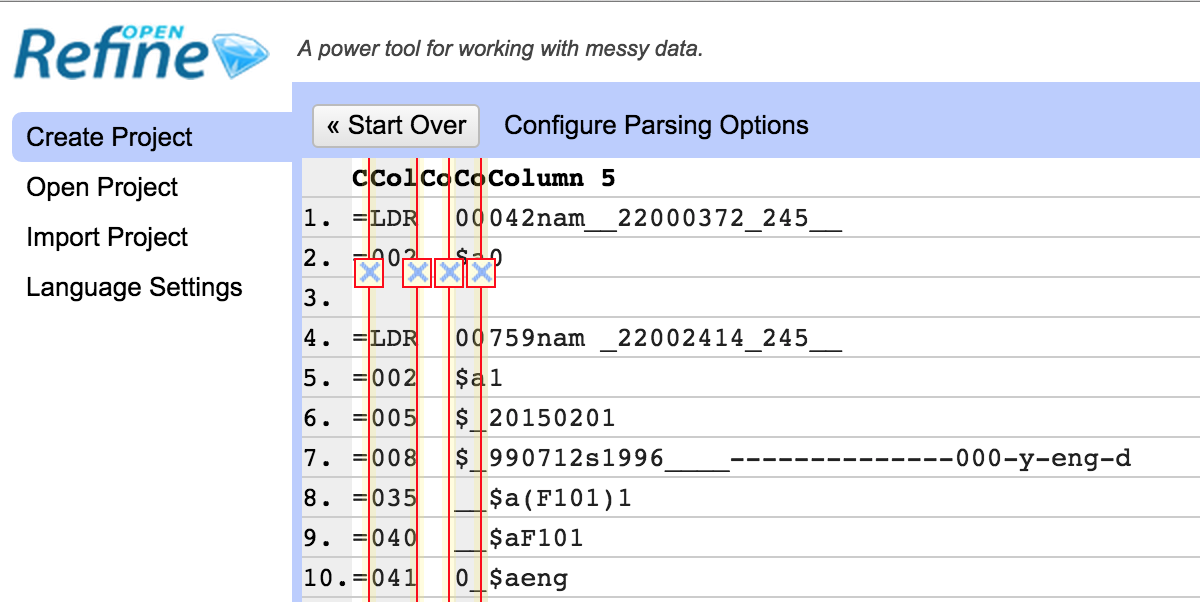
The mnemonic MARC format looks like this:
=LDR 00759nam _22002414_245__
=002 $a1
=005 $_20150201
=008 $_990712s1996____--------------000-y-eng-d
=035 __$a(F101)1
=040 __$aF101
=041 0_$aeng
=082 04$220$a630.7096881
=245 10$aExtension staff handbook;$nVolume II.
=260 __$aWindhoek :$bMinistry of Agriculture, Water and Rural Development,$c[1996]
=300 __$aca. 276 p. :$bill.
=852 __$aF101$c630.7096881 EXT
=110 2_$aNamibia.$bMinistry of Agriculture, Water and Rural Development.
=650 _0$aHorticulture$zNamibia.
=650 _0$aAgricultural extionsion work$zNamibia.
=650 _0$aAgroforestry$zNamibia.
=650 _0$aCrops$zNamibia.
=650 _0$aPests$xControl$zNamibia.
=650 _0$aSoil science$zNamibia.
=LDR 00289nam _22001214_245__
=002 $a2
=005 $_20150202
...
As you can see, each line starts with the same layout – an equals sign, three digit/letter tag, two spaces. There are then either the first two characters of a fixed field, or two indicators, the the content of the MARC field with subfields marked with ‘$’ signs.
The other thing to note is that a new record is indicated by a blank line.
This layout makes it easy to import into OpenRefine using the “Fixed-width field text files import” option – this format assumes a standard format for each line which we basically have here. You can set the places where you want to split each line into columns by clicking in the appropriate place.
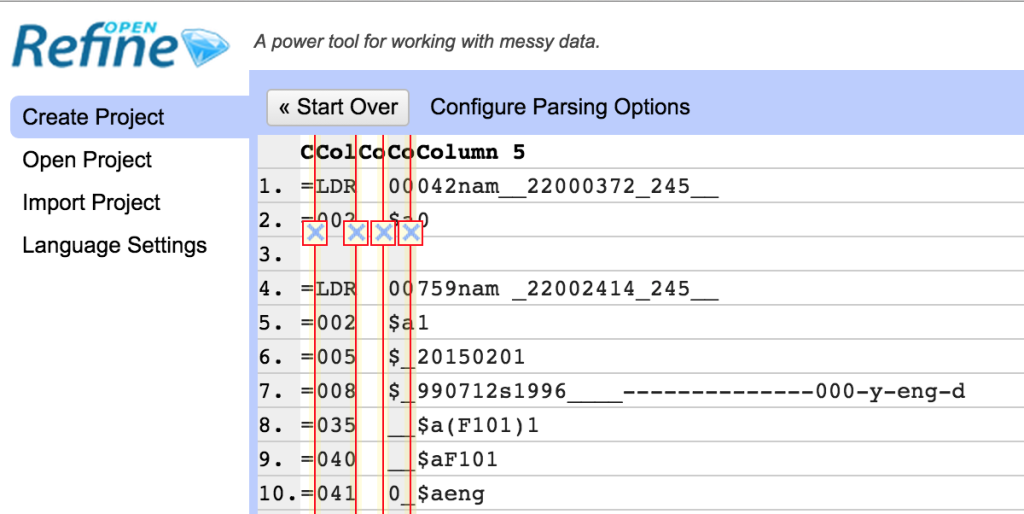
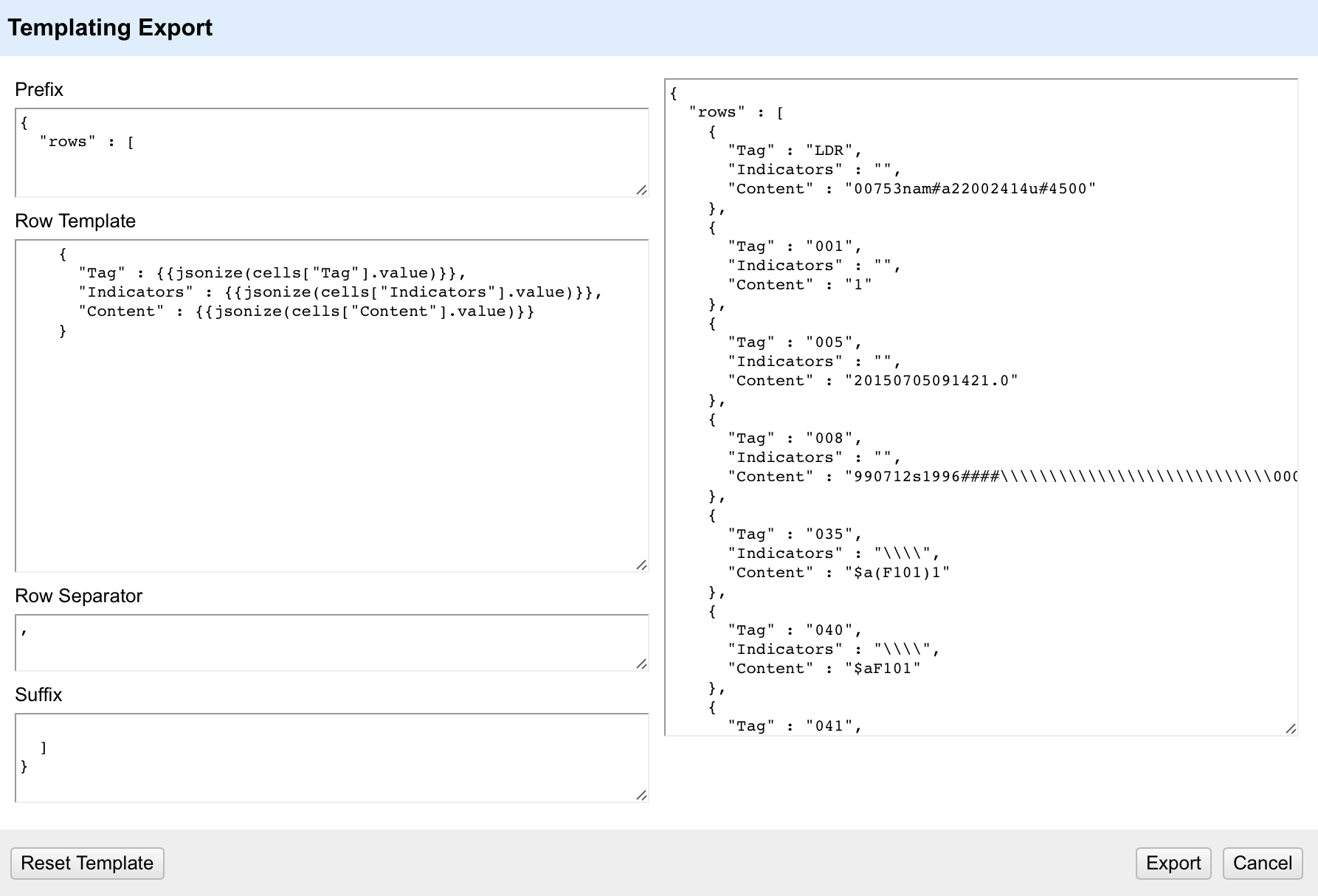
I split the file up as shown here – so I’m going to get one column with the MARC tag in, one that will generally include the indicators (for the non-fixed width fields) and then a last column with the content of the MARC field (the two other columns I’ll get contain the ‘=’ and the spaces between the tag and the indicators).
I immediately removed the columns without any real data in them, and renamed the columns to ‘Tag’,’Indicators’ and ‘Content’.
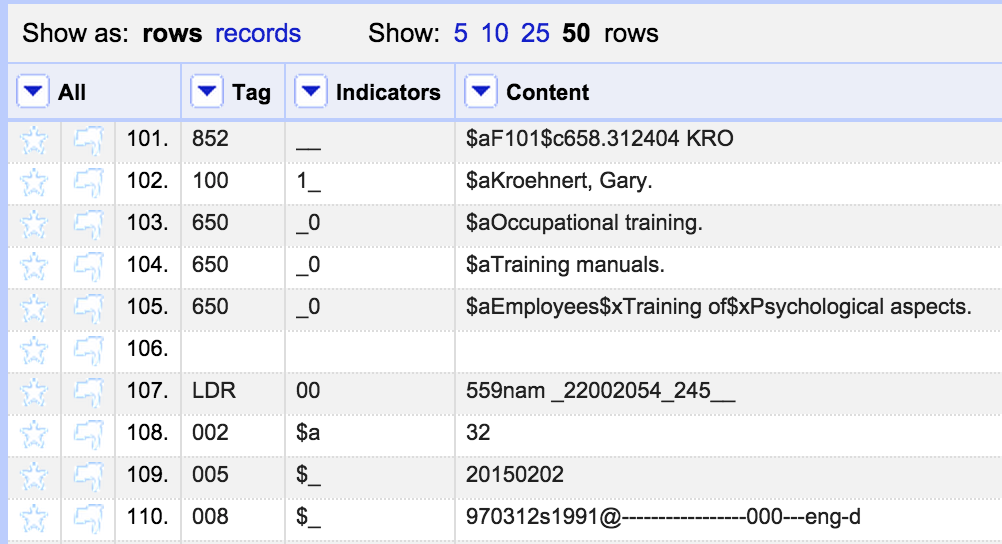
The lines between records are empty, as you can see in the screenshot above. As long as I keep these rows in order, and maintain the order of the file then this will easily export back to the MARC mnemonic format.
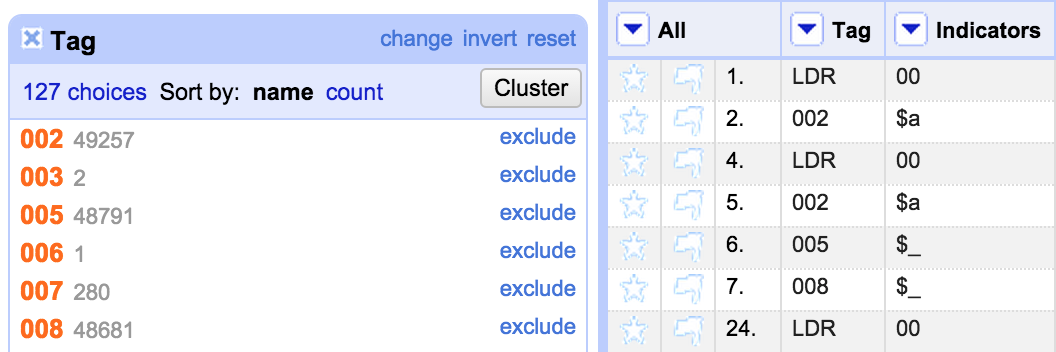
However, this approach has lead to some characters from the fixed fields in the ‘Indicators’ column rather than in the ‘Content’ column. So the first thing I do is to fix this. Firstly I create a Facet on the ‘Tag’ Column:
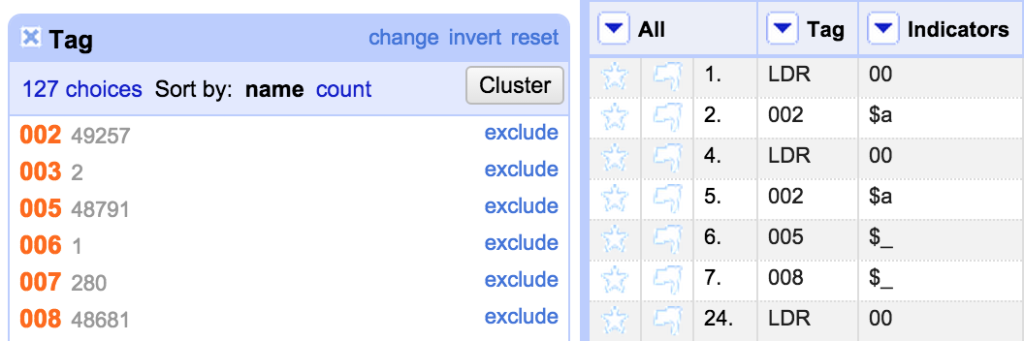
I used the facet to select the fixed fields and I could then see where (for some unknown reason) the file had a subfield at the start of a fixed field, I was able to use another facet on the Indicators column to see what values were there:
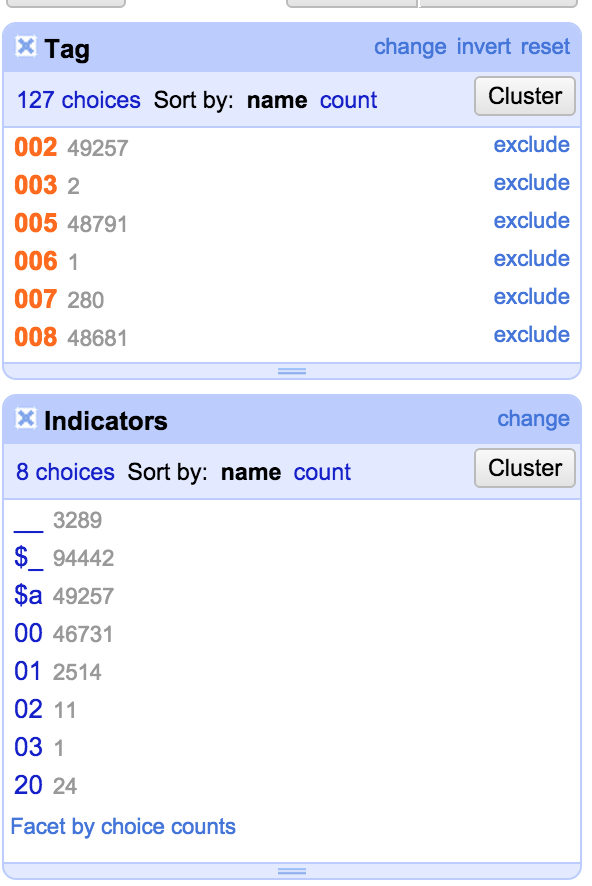
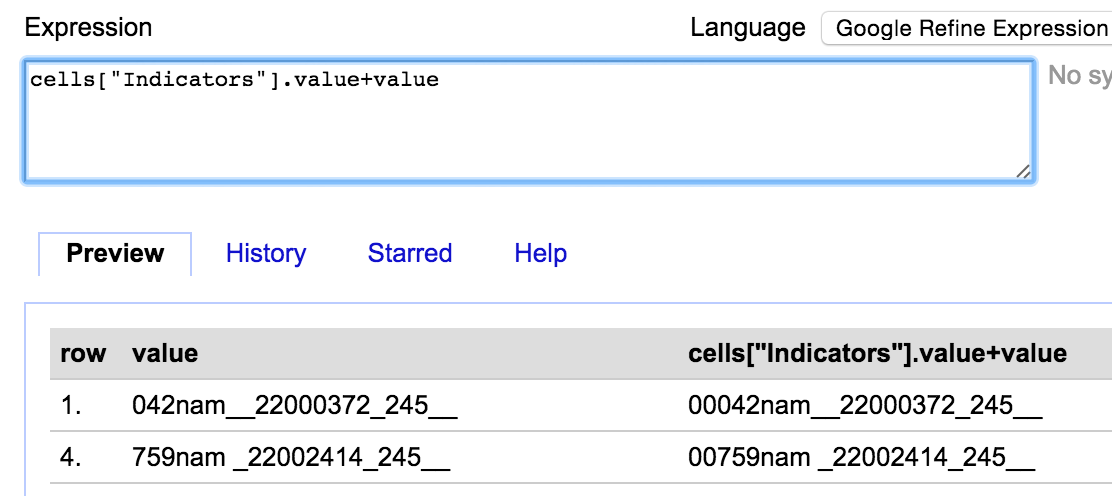
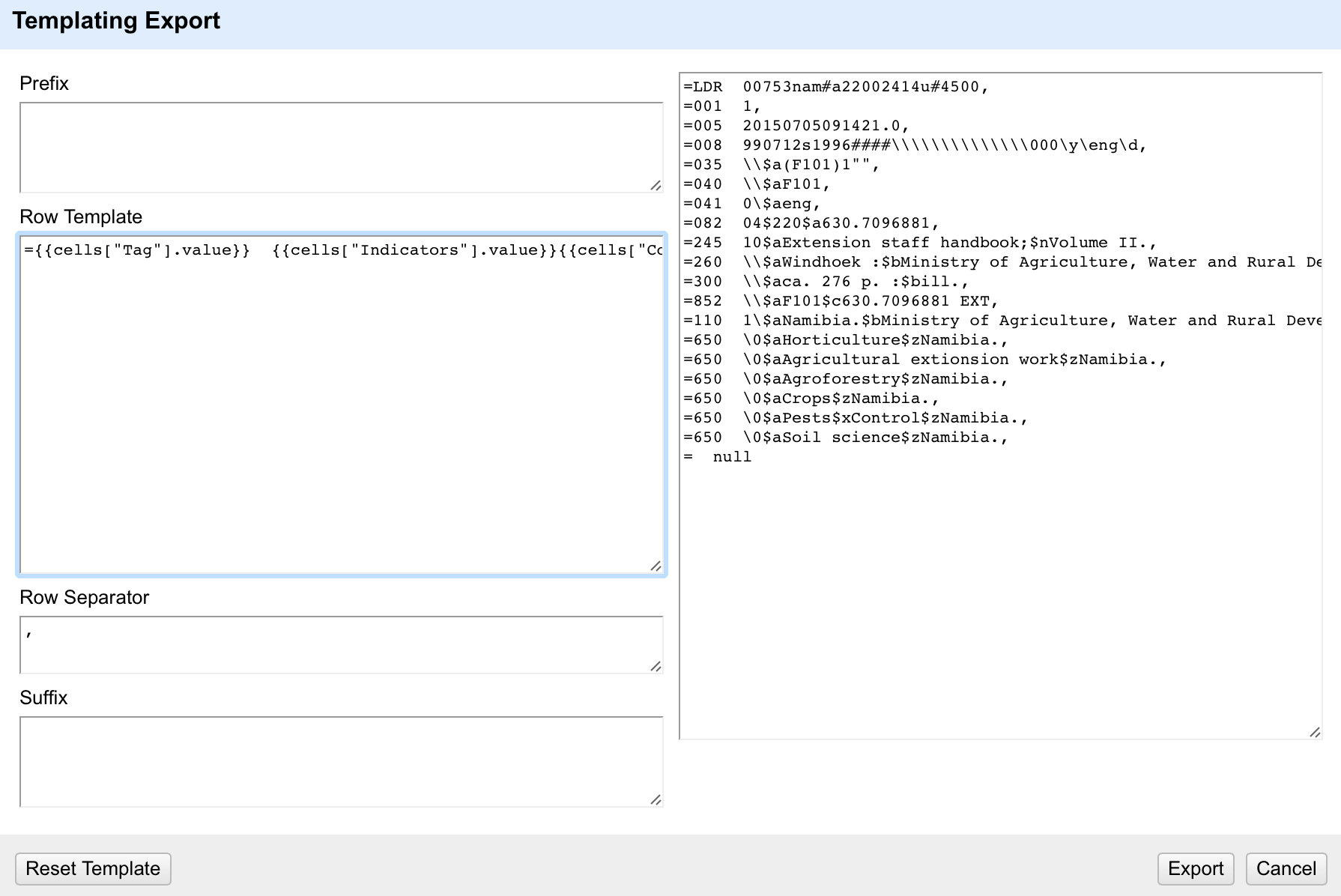
All the ‘Indicators’ that started with a ‘$’ I was able to just remove (by clicking ‘edit’ in the Indicators facet and just deleting the contents). Once I’d done this I was left with the situation where, for the fixed field, the contents of the Indicators column should actually be the first two characters of the ‘Content’ column. So the next job was to fix this. I made sure that the I was only working with the rows where the characters were misplaced (using the facets to select the right rows) and then I used the ‘Edit cells’->’Transform’ option for the ‘Content’ column and used the GREL expression:
cells["Indicators"].value+value
This takes the value from the Indicators column, and puts it in front of the value in the Content column:
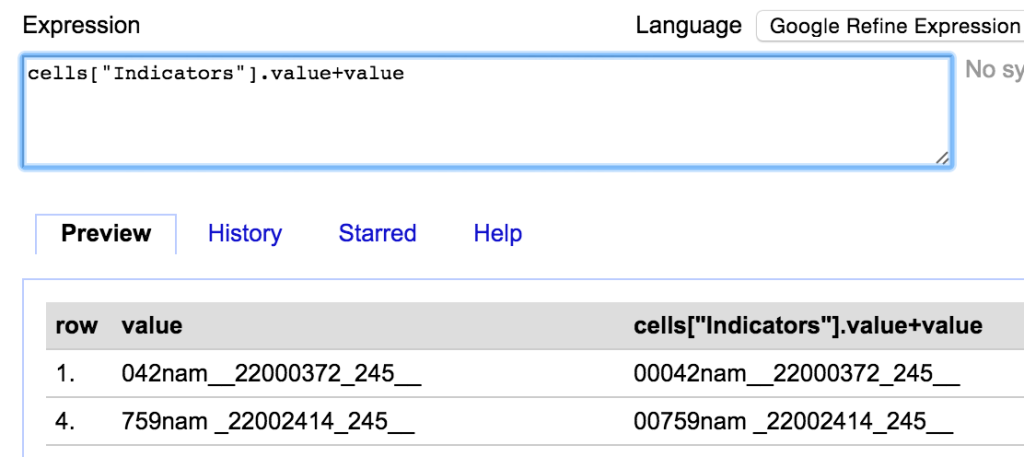
I could then get rid of the values from the Indicators column (again just for the filtered rows).
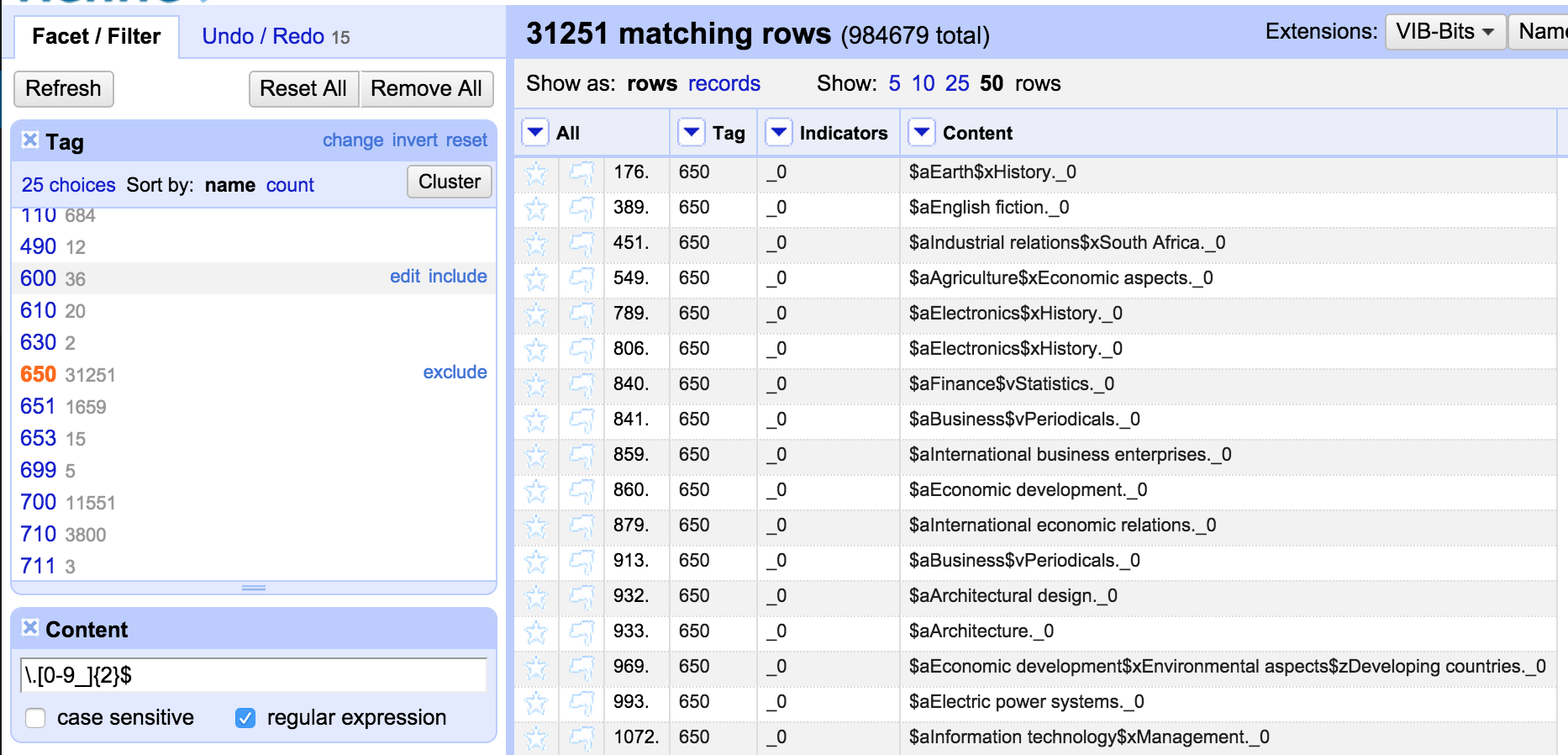
The next thing I’d noticed was that some fixed fields still had subfield indicators at the start. I wanted to find all fixed fields starting with a ‘$’ symbol. I could do this using a ‘text filter’:
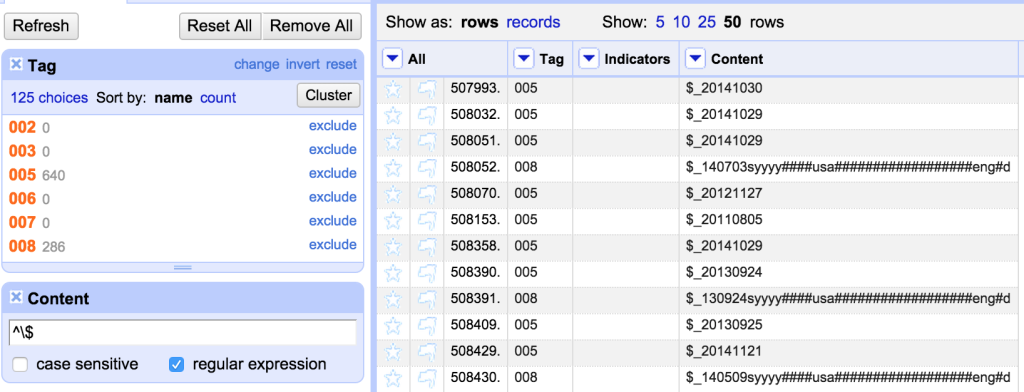
I’ve used a regular expression in the Filter which allows me to find only rows that start with the ‘$’ symbol (as opposed to having ‘$’ anywhere in the string).
All the lines I can see start with ‘$_’ but I want to check that there are no other patterns that I might need to take account of. I did this with a ‘Custom Text Facet’ on the Content column (Custom Facets are one of my favourite features and I use them a lot):
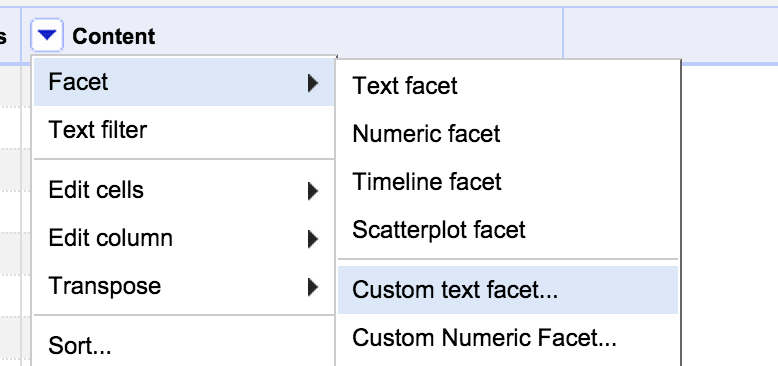
The Custom text facet allows you to create a facet by writing a GREL expression. I use the expression:
value.substring(0,2)
Which creates a facet with the first two characters from each cell – this immediately tells me that out of the rows I’ve filtered, they all start with “$_”:
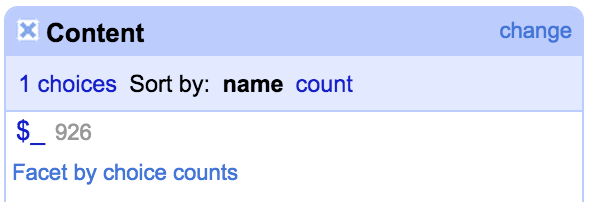
So I could now confidently run a transformation on the Content column to remove the first two characters for all these rows – using:
value.substring(2)
Which takes the whole of the string excluding the first two characters.
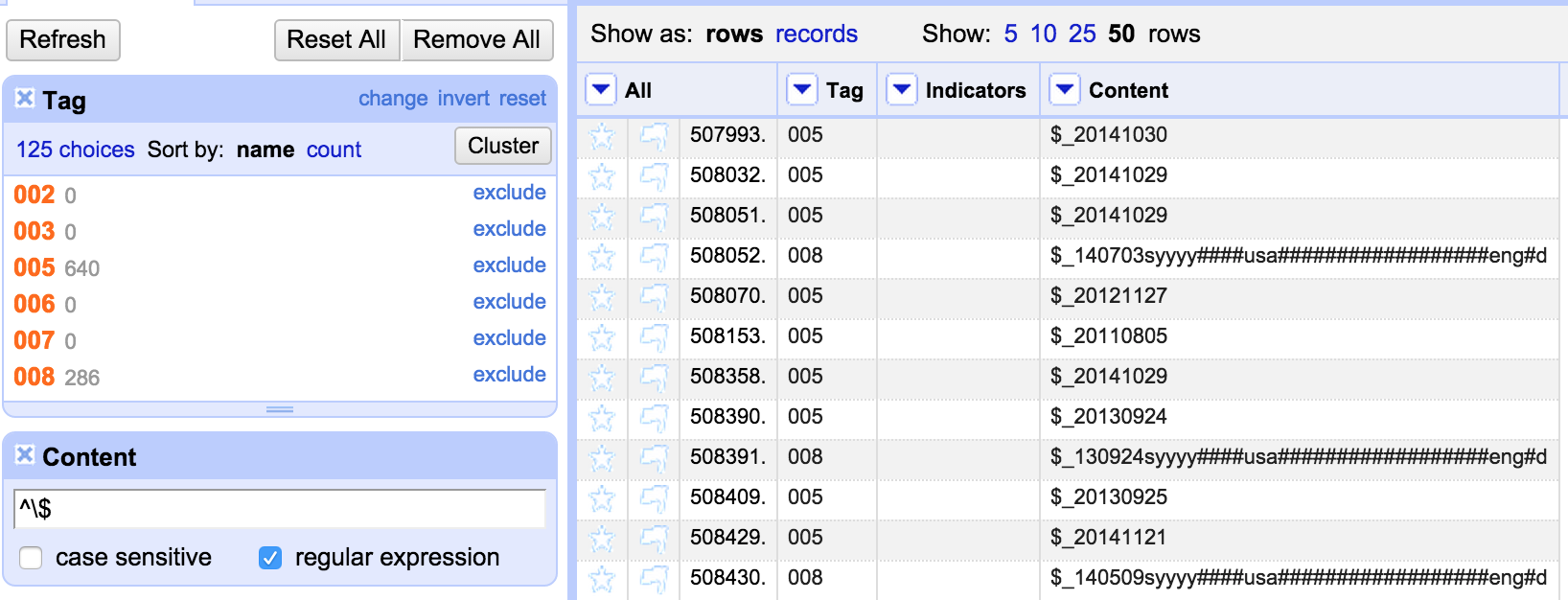
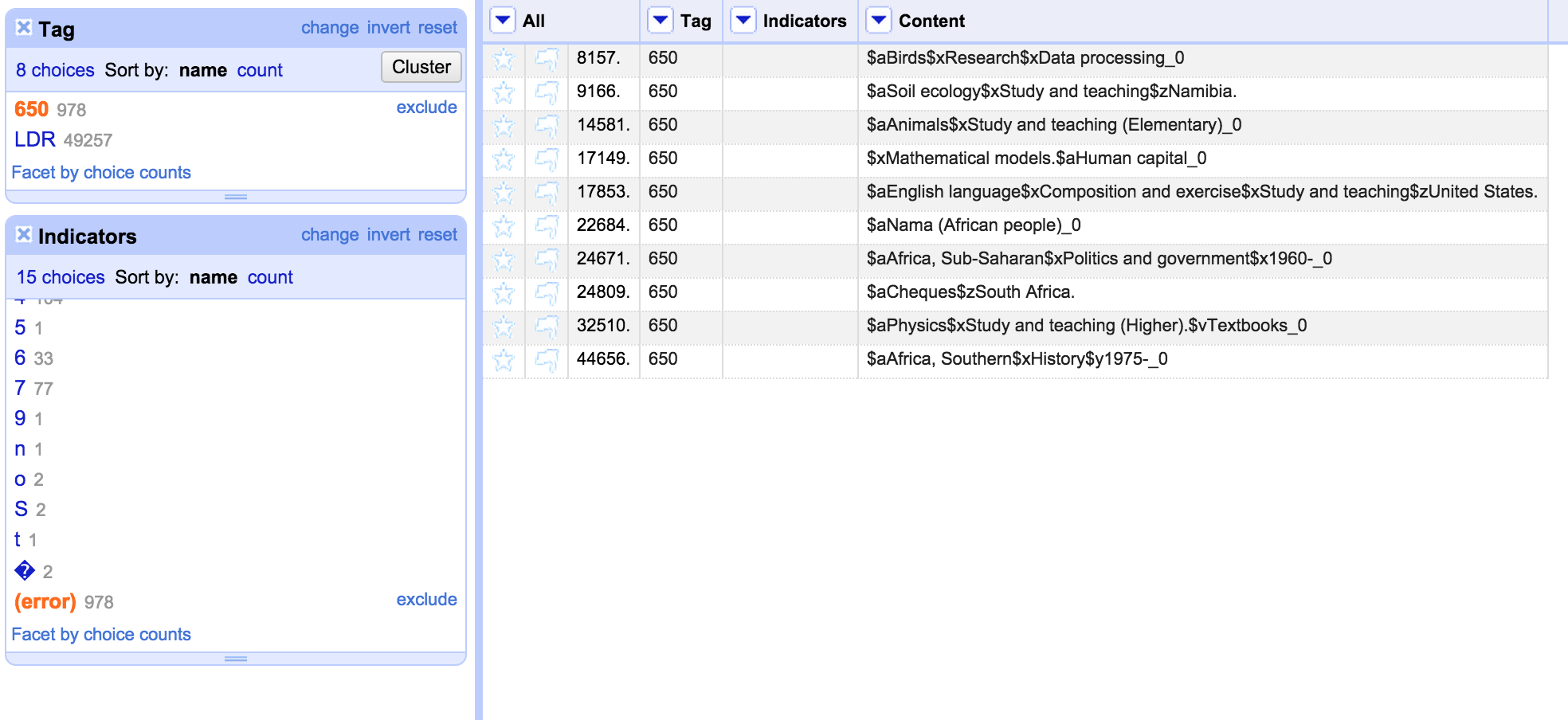
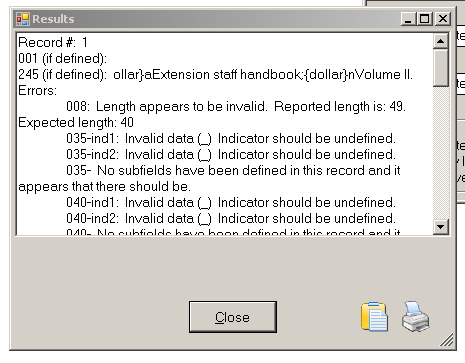
From the errors file (which I also opened in OpenRefine in a separate project which allowed me to group the errors easily) I could see situations where there were incorrect indicators for a MARC field (and other errors) – and I could use the facets to filter down to the field in question, and then look at the issues with the indicators – and fix them. I’m not going to describe every single situation, but one example was the 650 field. Here for some reason the indicators seemed to have been shifted to the end of the field, rather than appearing at the start of the field. This, in turn, had lead to the first subfield appearing where the indicators should have been:
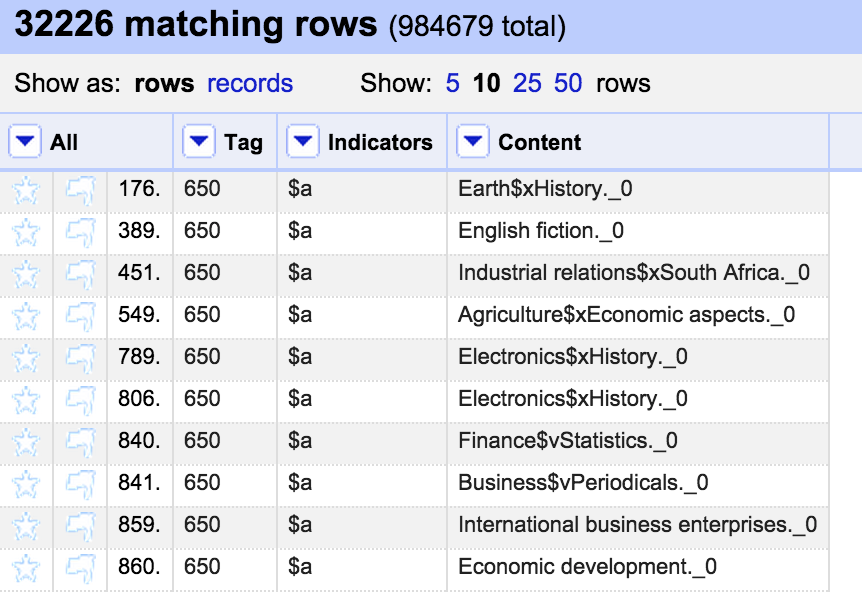
So here I want to move the contents of the ‘Indicators’ column into the Content column. I did this with the same approach as described above. Then I wanted to move the indicators from the end of the string into the Indicators column. I used a Filter with a regular expression to find 650 fields ending with a digit or an ‘_’ which seems to be used generally for uncoded indicators:
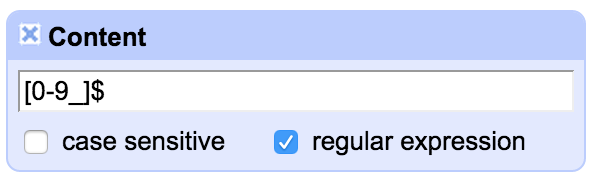
This seems to give me what I need:
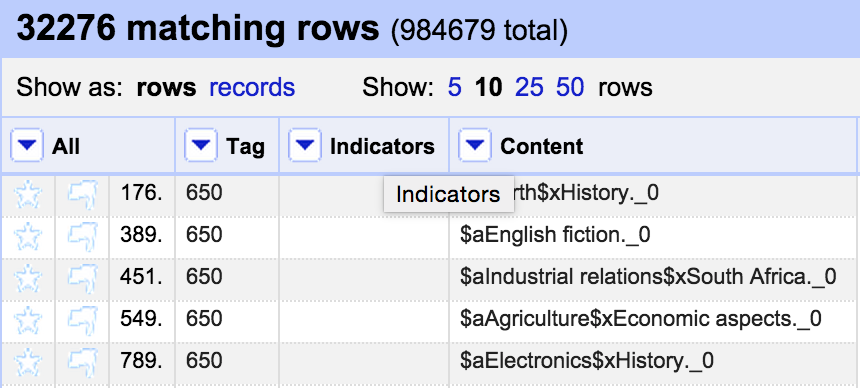
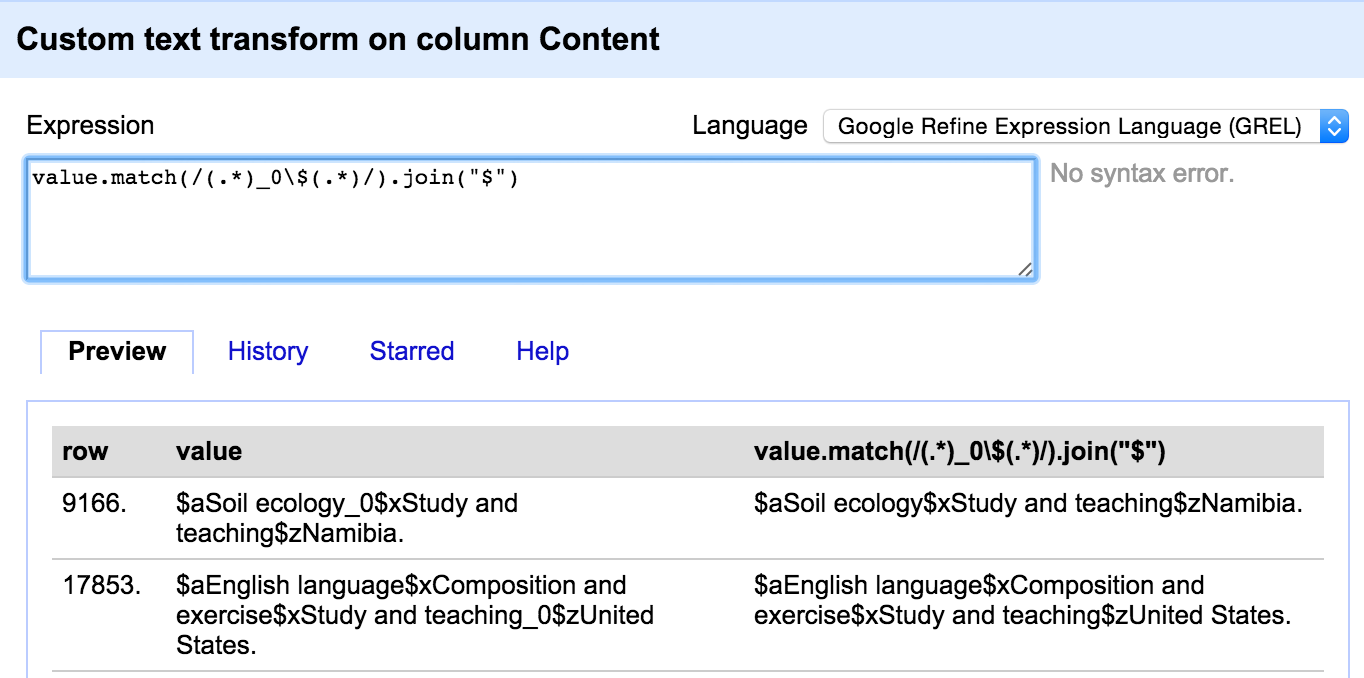
So now I can run a transformation on the Indicators column:
cells["Content"].value.substring(-2)
Which inserts the last two characters from the Content column into the Indicators column.
However, after doing this, I realised that this had ended up including some situations where the 650 field finished with a year (hence ending with two digits). So I used the ability of OpenRefine to reverse my last steps, and then I improved my filter and made sure I didn’t include those rows and then re-applied the transformations:
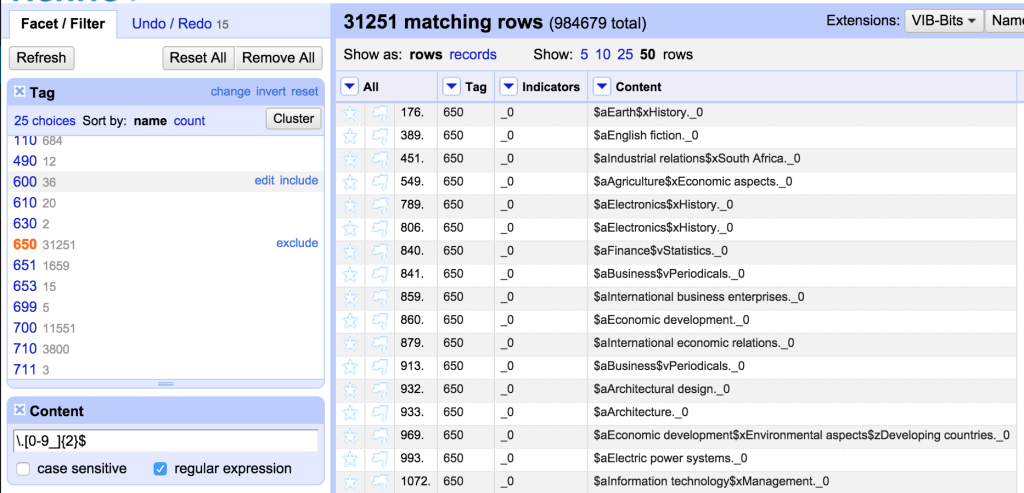
As you can see in this screen shot – this transformation is being applied to over 30,000 650 fields in one go.
A lot of the issues in the MarcEdit Validation report were incorrect indicators on various fields. I could see from this that there were problems with the second indicator on the 650 field in some cases. To investigate this I created a new custom text facet using the expression:
value[1]
This takes the second character in the ‘value’ (lots of stuff in OpenRefine counts from zero – value[0] is the first character from value, and value[1] takes the second). I used the ‘Tag’ facet to filter down to the 650 field, and then I could see where there were problems:
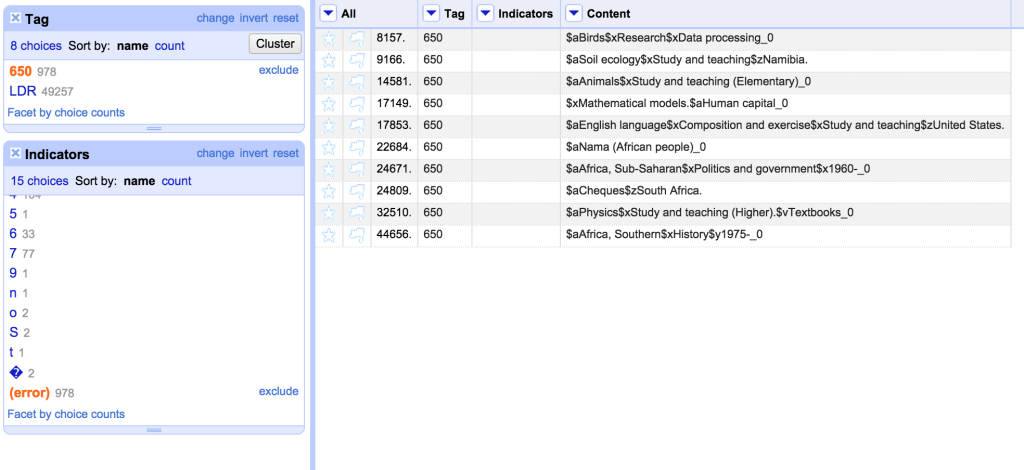
I can see that there are lots of 650 fields which have no second indicator (and for some reason haven’t been caught by my previous expression) and also some odd stuff like ‘9’, ‘n’ and ‘S’. These need investigating individually. However, you can see how this method could be used to check for incorrect indicators and look for patterns to fix them.
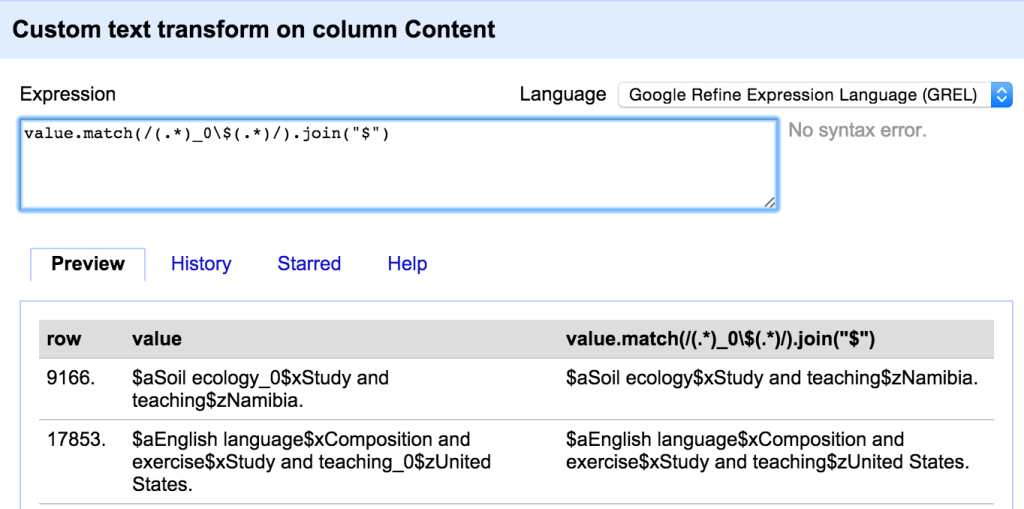
While there were many more issues to work through, the techniques were pretty much what I’ve already described here – lots of use of filters, facets, custom facets, substring and replace transformations. There were also situations where I wanted to find and extract values from the middle of a MARC field and in this case I used the ‘match’ transformation with a regular expression – for example here I’m using a ‘match’ transformation to remove some indicators that have somehow ended up in the middle of a MARC field:
For the LDR and 008 fields I was able to check various character positions using custom text facets with the ‘substring’ command. I was also able to check the length of these fields using a custom text facet with:
value.length()
All of these showed me problems that I could work on fixing.
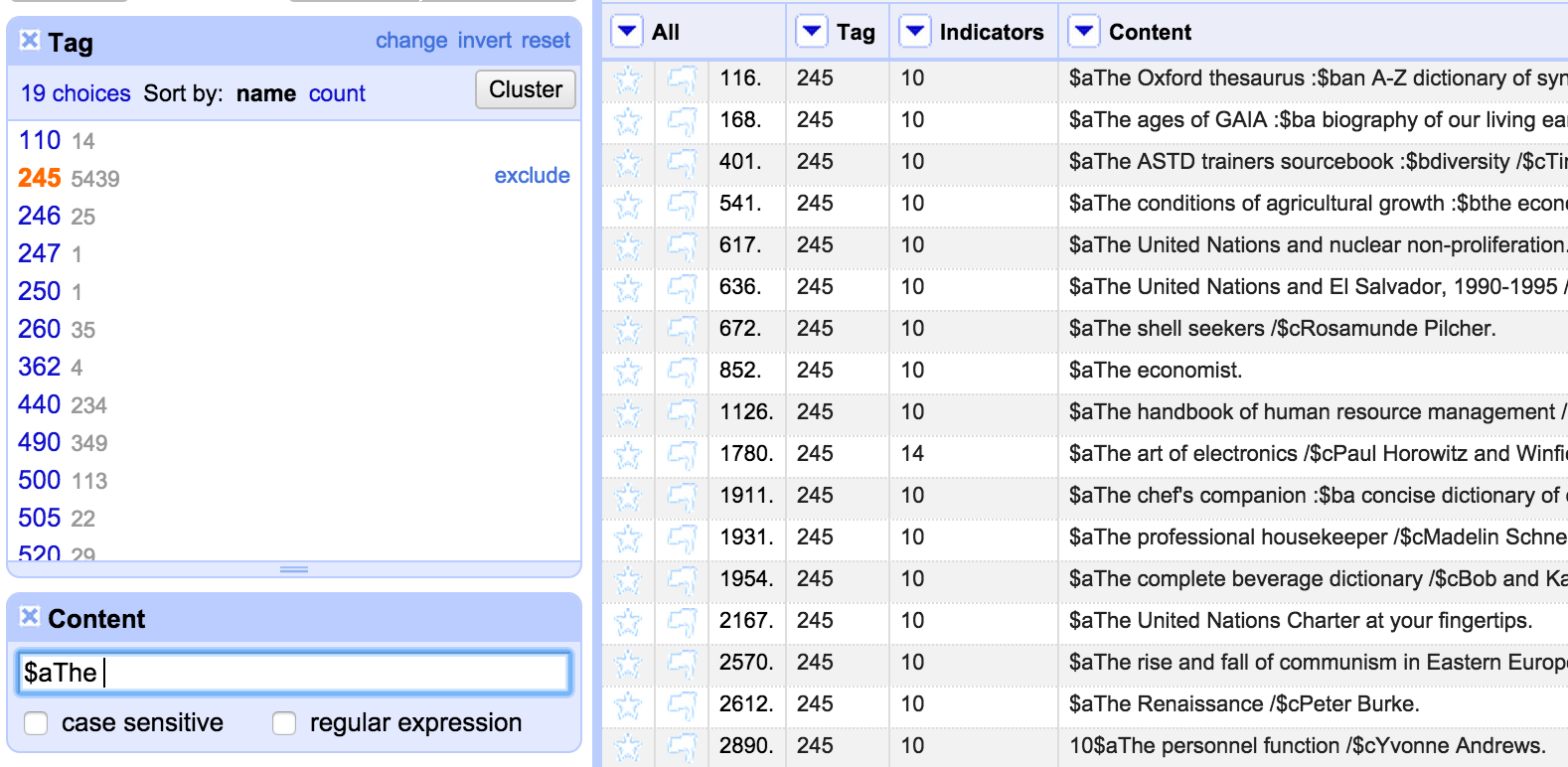
I want to share one final example in this post – because while the records I was dealing with here were obviously really messy, and invalid, and hopefully not issues you’d see in most MARC data, while I was dealing with the records I noticed some of the 245 fields had incorrect non-filing indicators. Despite the fact this wouldn’t affect the validity of the records, I couldn’t ignore these, and so I thought I should look for any examples of this and fix them. So I used the Tag facet to get the 245 field only, and then started playing around with filters intended to find potential non-filing words at the start of the field. I started by looking for 245 fields that started with a $a subfield followed by the word ‘The’:
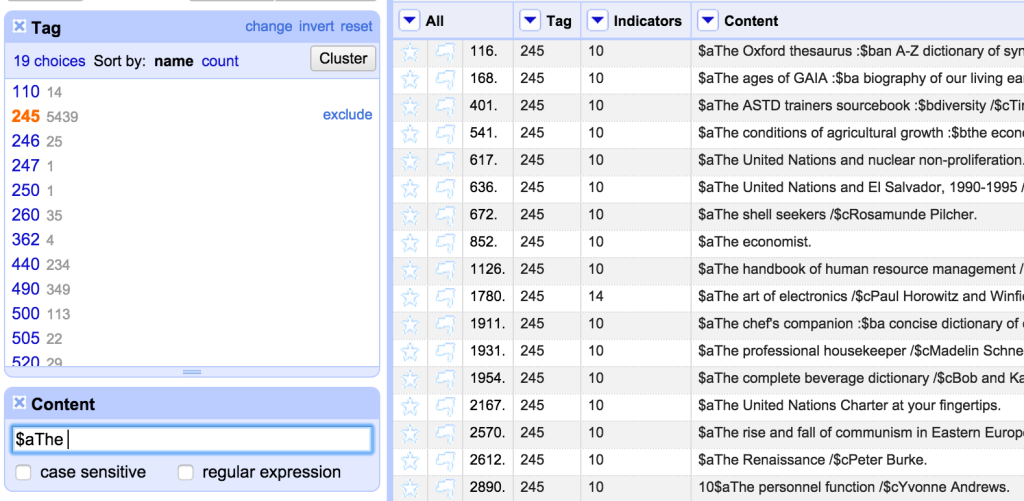
As can be seen, the indicators are incorrect for most of these. So I could fix these in one go by setting the second character in the indicator column to ‘4’ using the following expression on the Indicator column:
value[0]+"4"
(value[0] takes the first character from whatever string is in the column currently – I want to preserve this as it is, and only change the second character)
I then got a bit more inventive with the Filter – doing things like looking for 245$a starting with one, two or three letter words, then identifying common patterns (essentially definite and indefinite articles in various languages) and fixed those as well.
This kind of small data fix might apply to any set of MARC records where some inconsistencies and typos will have occurred.
After a lot (a lot!) of work, I’d finally fixed up the records as far as I could. There were circumstances where I’d had to make my best guess (were those ‘650’ fields really LCSH?) but generally I was pretty happy with what I’d achieved. It was time to export the records from OpenRefine and get them back into MarcEdit to validate them again… which I’ll cover in Part 5.




{kind=link}